
Building a Memory Operating System for AI
There is a quiet frustration that every developer working with AI eventually encounters: you spend hours teaching it your codebase, your patterns, your business rules — and the next morning, it remembers nothing. Every session starts from zero. Every explanation must be repeated. Every lesson is lost.
I refused to accept this.
What started as a simple folder of markdown notes beside my code became something I did not expect: a full operating system for memory — not inside the AI, but around it. I call it the Mind System, and after weeks of relentless iteration, it has become the most valuable piece of infrastructure I have ever built.
This is the story of how it evolved.
The First Instinct: Just Write Things Down
It began with a .mind/ directory. Nothing ambitious. Just a place to drop notes about what I was working on — business rules, implementation decisions, patterns I wanted the AI to follow. Plain markdown files with no structure, no naming convention, no governance.
It worked for about two days.
The problem was not volume. It was retrieval. When you have thirty documents and no structure, you can still find things by scrolling. When you have three hundred, you cannot. And when the AI assistant is the one trying to find relevant context at the start of each session, “just search everything” leads to drowning, not understanding.
The first insight arrived: the bottleneck is not what you know — it is what you can find at the right moment.
Frontmatter: Giving Documents a Contract
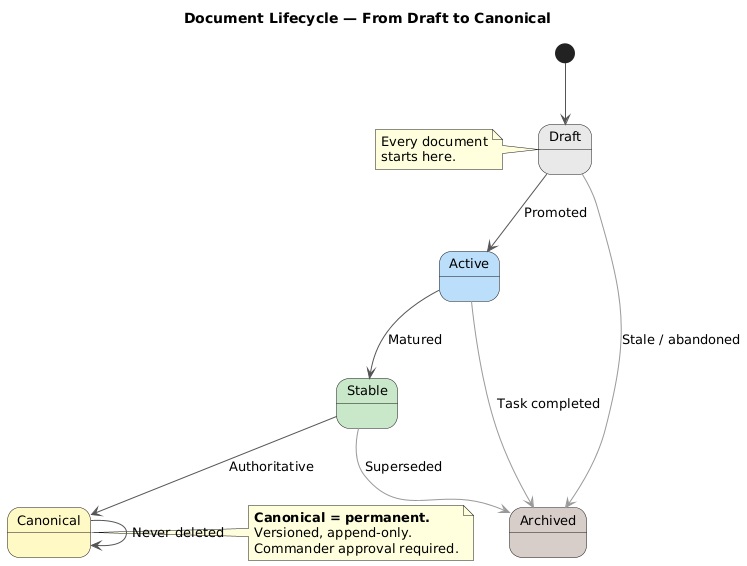
The first real architectural decision was adding YAML frontmatter to every document. Not as decoration — as a queryable contract. Every file declared its type (knowledge, plan, decision, learning), its status (draft, active, stable, canonical, archived), and which domain it belonged to.
This was not a tagging system. It was a governance layer. The frontmatter turned a flat folder of files into a structured knowledge base where documents could be filtered, sorted, classified, and — critically — where their lifecycle could be managed.
A document was no longer just text. It was an object with metadata, and that metadata could be enforced by scripts.
The CLI: A Control Plane for Memory
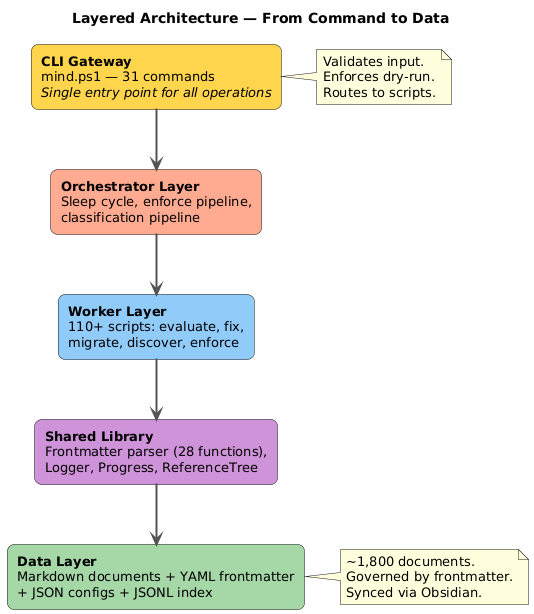
The folder grew. I needed a way to navigate it that was faster than browsing, more precise than search, and more structured than file names. So I built a command-line interface.
The first version had eight commands. List files by status. Show statistics. Check system health. Promote a document’s lifecycle status. Archive stale content. It ran in PowerShell and parsed frontmatter from every file in the directory.
Within days, it grew to fifteen commands. Then twenty. Then thirty-one. Search by content. Find documents by ticket reference. Show a file’s metadata and preview. Set frontmatter fields with validation. Compute impact analysis across four layers. Build reference graphs. Detect orphan documents.
The CLI became the single entry point for all interactions with the knowledge base. Not because command lines are fashionable, but because a single entry point means a single place to enforce rules, validate schemas, log operations, and maintain audit trails.
Eventually, I added a rule that changed everything: all document creation and modification must go through the CLI. No direct file editing. No bypassing the governance layer. If the CLI cannot do something, the correct response is to enhance the CLI — not to work around it.
This single rule transformed the system from a knowledge base into a governed platform.
Three Tiers: Wisdom, Meta-Knowledge, and Knowledge
As the system grew, I noticed that not all documents are equal. Some contain business rules that must never be violated. Some define how the system itself should be structured. Some capture what the AI learned during a work session.
These are fundamentally different categories, and they need fundamentally different governance:
Wisdom sits at the top. These are non-negotiable principles — the rules that override everything else when conflicts arise. Only the human (I call this role the Commander) can write wisdom. The AI reads it, respects it, but never modifies it.
Meta-Knowledge governs the structure itself — the frontmatter schema, the classification rules, the lifecycle definitions, the sleep cycle configuration. Both the human and the scripts can modify this layer. It is the constitution of the system.
Knowledge is where the actual content lives — business domain documents, implementation plans, technical patterns, learning syntheses. The AI and scripts operate freely here, under the constraints set by the layers above.
The insight: Knowledge grows horizontally. Meta-Knowledge grows vertically. Wisdom grows inward. Most systems scale only the first. The ones that endure scale all three.

The Sleep Cycle: Automated Self-Maintenance
A knowledge base that only grows will eventually collapse under its own weight. Documents go stale. References break. Metadata drifts. Patterns emerge that no one has formalized. This is entropy, and entropy always wins unless you actively fight it.
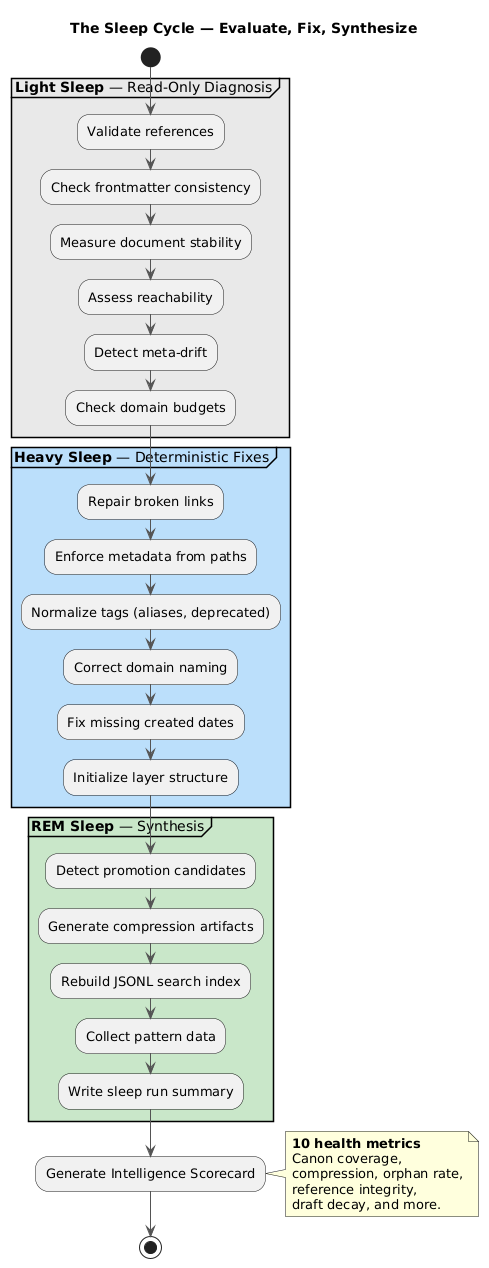
I built a sleep cycle — a multi-phase automated maintenance process that runs periodically:
Light Sleep evaluates without changing anything. It validates references, checks frontmatter consistency, measures document stability, assesses reachability. It is a read-only diagnostic.
Heavy Sleep fixes what Light Sleep found. It repairs broken links, enforces metadata from directory paths and content analysis, normalizes tags, corrects domain naming, and restructures what has drifted.
REM Sleep synthesizes. It detects documents ready for promotion. It identifies patterns across learning syntheses. It generates compression artifacts — condensed canonical references from sprawling domain knowledge. It rebuilds the search index.
The analogy is deliberate. The human brain consolidates memory during sleep. This system does the same — except deterministically, with scripts, not neurons.
Over time, the sleep cycle grew to orchestrate over 120 scripts across multiple phases. Some run in seconds. Some process thousands of files. All report their findings. The system, in a very literal sense, maintains itself.
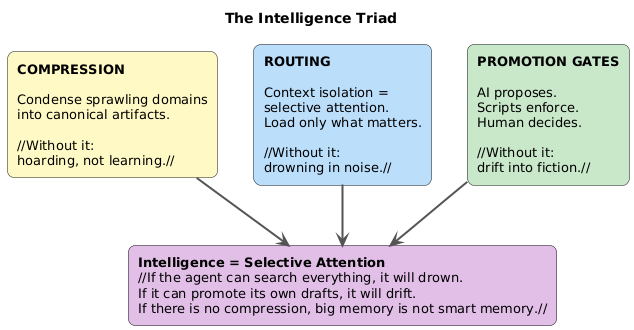
The Intelligence Triad: Compression, Routing, Promotion
After weeks of building, testing, analyzing, and rebuilding, a doctrine crystallized that I believe is the most important insight of the entire project:
The intelligence will not come from the AI remembering everything. It comes from the system governing what the AI is allowed to see, write, and promote.
This is not memory inside the model. This is memory as an operating system around the model.
The doctrine rests on three pillars:
Compression — every domain must eventually produce condensed, canonical artifacts. Without compression, you are hoarding, not learning. A thousand documents about the same domain is not knowledge; it is noise with ambition.
Routing — context isolation is selective attention. At the start of every session, the system loads only the documents relevant to the current task. If the AI can “search everything,” it will drown. Loading the right ten documents is infinitely more valuable than having access to ten thousand.
Promotion Gates — the AI proposes, scripts enforce, the human decides. The AI can create drafts, synthesize learnings, suggest patterns. But it cannot promote its own work to authoritative status. Without this gate, the system drifts into fiction. With it, every canonical document has earned its place.
Intelligence equals selective attention. This is true for humans. It is true for AI systems. And it is true for knowledge bases.
Nine Waves of Self-Discovery
One of the most unexpected chapters in the system’s evolution was when I turned the CLI’s analytical capabilities inward — using the Mind to analyze itself.
Over nine waves of increasingly sophisticated analysis, the system discovered over seventy categories of issues across more than a hundred individual analyses. Broken references. Orphan documents. Tag system corruption. Lifecycle stalls where documents were stuck in draft status indefinitely. Knowledge islands with zero outbound connections. Scripts without error handling. Duplicate content clusters.
The knowledge graph turned out to be 99.6% connected — a single giant component of 1,775 nodes out of 1,783. That was a structural victory. But the script ecosystem had 30% dead code and an 88% dependency on a single shared library — a brittleness that the documents themselves did not have.
The score after all this analysis: 69 out of 100. Good, not great. The gaps were clear: compression coverage at 0%, too many documents stuck in active status, meta-drift in several areas. But the score itself was less important than the fact that the system could measure itself.
A system that can diagnose its own health is fundamentally different from one that cannot.
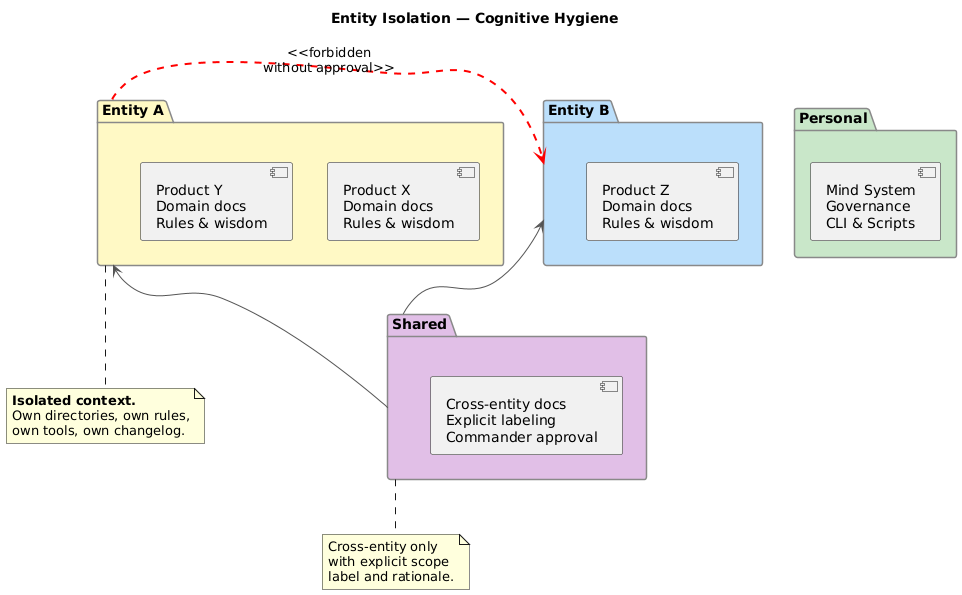
Entity Isolation: When One Mind Serves Many Masters
The system does not serve a single project. It serves multiple business entities, each with different domains, different tools, different compliance requirements. This created a problem: without strict boundaries, knowledge from one context would leak into another. The AI would apply patterns from one business to a completely different one.
The solution was entity isolation — enforced at every level:
- Directory structure mirrors the entity hierarchy
- Frontmatter explicitly declares which entity and product each document belongs to
- The CLI filters by entity before returning results
- Scripts validate that files under one entity’s directory do not carry another entity’s metadata
- Cross-entity documents are allowed only in a shared directory with explicit labeling
- At the start of every session, the system asks: which entity, which product, which task, which environment?
This is not just organizational tidiness. It is cognitive hygiene. When the AI loads context for one business, it should not be influenced by another business’s rules. Entity isolation makes this structural rather than aspirational.
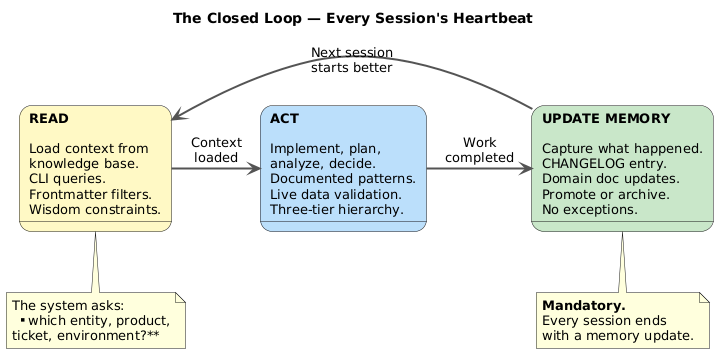
The Closed Loop: READ, ACT, UPDATE MEMORY
Every interaction with the system follows a mandatory feedback loop:
READ — load relevant context from the knowledge base before doing anything. The CLI provides the queries. The frontmatter provides the structure. The wisdom provides the constraints.
ACT — implement, plan, analyze, or decide. Use the documented patterns. Validate against live data when available. Follow the three-tier hierarchy: wisdom overrides meta-knowledge, which overrides knowledge.
UPDATE MEMORY — capture what happened. Write to the changelog. Update domain documents. Add frontmatter to new files. Promote or archive what needs it. This is not optional. Every session ends with a memory update. No exceptions.
The loop is the system’s heartbeat. Without it, knowledge decays. With it, every session leaves the system slightly better than it found it.
What I Learned Building a Memory Operating System
Building this system taught me things that no architecture diagram could convey:
Structure is not bureaucracy. When people hear “YAML frontmatter on every file” and “CLI-only document operations,” they think overhead. In practice, the structure is what makes the system fast. A structured query against frontmatter takes milliseconds. A free-text search through a thousand documents takes seconds and returns noise.
Deterministic systems beat stochastic ones for governance. The AI is brilliant at generating content, synthesizing patterns, and connecting dots. It is terrible at maintaining consistency over time. Scripts do not hallucinate. Scripts do not forget rules between sessions. Scripts do not gradually drift from the schema. For everything structural, deterministic tools are not just better — they are the only reliable option.
Decay is the default. Every system trends toward disorder unless actively maintained. The sleep cycle is not a luxury. It is the force that opposes entropy. Without it, three months of growth would produce an unmaintainable mess.
Measuring matters. The intelligence scorecard — ten metrics computed after each sleep cycle — transformed how I think about the system. Canon coverage. Compression coverage. Orphan rate. Reference integrity. Draft decay. Each metric tells a story. Together, they tell the system’s story.
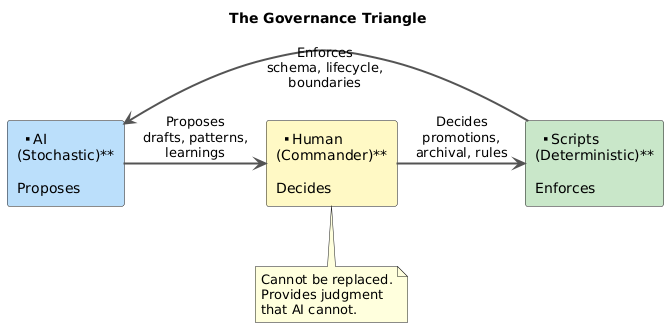
The human remains essential. The Commander role is not ceremony. It is the recognition that AI systems need a governor. The AI proposes brilliantly but cannot distinguish its own confident fiction from verified truth. The human provides that judgment. The scripts enforce the decisions. This triangle — propose, decide, enforce — is the architecture of trustworthy AI-assisted work.
Where It Stands Today
The Mind System currently comprises:
- 31 CLI commands spanning navigation, inspection, mutation, classification, lifecycle management, and maintenance
- 121 PowerShell scripts for evaluation, migration, enforcement, and automated sleep cycles
- A shared library of 28 reusable functions for frontmatter parsing, logging, progress tracking, and reference graph operations
- ~1,800 documents organized across multiple entities and products, each with governed YAML frontmatter
- A three-tier cognitive architecture that separates human wisdom from structural governance from operational knowledge
- An automated sleep cycle that evaluates, fixes, and synthesizes across all documents periodically
- An intelligence scorecard that measures ten dimensions of system health
- Context profiles that auto-detect which entity and product to load based on environment signals
It started as a folder with a few markdown files. It became a Memory Operating System.
The Name
I call it a Memory Operating System because that is precisely what it is. Not a note-taking app. Not a knowledge base. Not a wiki. An operating system — with a kernel (the CLI), a filesystem (the document corpus), a scheduler (the sleep cycle), process isolation (entity boundaries), access control (the three-tier architecture), and self-diagnostics (the scorecard).

The operating system does not run on a CPU. It runs on the boundary between human cognition and artificial intelligence. Its job is not to make the AI smarter. Its job is to make the AI consistent, contextual, and accountable — session after session, task after task, month after month.
The intelligence does not live in the model. It lives in the system that governs the model.

